
A Developer's Story
This is going to be a longer, and in some ways, more technical post regarding the evolution of the BTPBuddy platform from a developer’s point of view.
Posts have been scarce from my end, so I wanted to take the time to introduce the architectural decisions made in building the platform, as well as to talk about certain successes and failures in the development lifecycle over the past several months.
Technical Refresher
Before diving into technical details, let us first restate our goal for our MVP and eventual end product.
With the rise of judicial problems for actors in the BTP industry (more specifically, PMEs, or small-to-medium sized companies) over the past couple of years, we sought out to pinpoint any downsides to the project management and workflow aspects of these companies.
After many interviews and research efforts, we concluded that what these PMEs were missing from a technological point of view was a document management tool; PMEs simply don’t have a go-to solution for efficiently managing a variety of types of documents related to their projects. This eventually leads to legal problems downstream when they are unable to surface important information, either digitally or physically.
With this in mind, we sought out to develop a cloud-based platform which enabled BTP PME actors to have a safe-haven for their project-related documents. Furthermore, we seek to offer these actors the full power of the cloud by exposing their documents to high fidelity tagging mechanisms which in turn marks the documents up with insightful metadata.
Thus, the idea of BTPBuddy platform came to life, and development needed to begin quickly…
System Architecture
From this technical refresher we can outline some bare-bones functional requirements for the platform:
- Allow clients, once registered with our platform, to create “Projects” which are essentially digital document containers.
- Enable clients to upload documents to the platform, attaching them to their created projects. This entails uploading the file itself, as well as supplying additional metadata such as the type of document (contractual, standard document, receipt, etc.), a description for the document, and most importantly, meta tags.
- These meta tags can be added manually at upload-time, or via automatic document tagging algorithms.
- Enable search-by-tag on the uploaded documents in order to more easily find documents by subject matter content.
- Keep a timeline of changes related to both the projects themselves, as well as the documents uploaded in the platform.
Like most web platforms, we need to establish three (+1) fundamental architecture layers: a database layer (DBL), a data-access or data-abstraction layer (DAL), and a front end. The +1 here is the integration of the DBL and DAL with the AWS cloud.

DBL
Our database layer is relational, and was built using MySQL.

The diagram above shows the tables used, as well as the relationships between them. Stored procedures were created in order to retrieve, update/add, and remove data from the tables, and followed a unique naming convention for organizational purposes.
# Stored procedures defined in MySQL:
# Get (SELECT) procedures
BTPBGetClient
BTPBGetClientType
BTPBGetProject
BTPBGetProjectDocument
BTPBGetProjectDocumentContent
BTPBGetProjectDocumentContentType
BTPBGetProjectDocumentTag
BTPBGetProjectDocumentType
BTPBGetUser
BTPBGetUserType
# Remove (DELETE) procedures
BTPBRemoveClient
BTPBRemoveClientType
BTPBRemoveProject
BTPBRemoveProjectDocument
BTPBRemoveProjectDocumentContent
BTPBRemoveProjectDocumentContentType
BTPBRemoveProjectDocumentTag
BTPBRemoveProjectDocumentType
BTPBRemoveUser
BTPBRemoveUserType
# Add/Update (INSERT/SET) procedures
BTPBUpdateClient
BTPBUpdateClientType
BTPBUpdateProject
BTPBUpdateProjectDocument
BTPBUpdateProjectDocumentContent
BTPBUpdateProjectDocumentContentType
BTPBUpdateProjectDocumentTag
BTPBUpdateProjectDocumentType
BTPBUpdateUser
BTPBUpdateUserType
These stored procedures are then referenced by the DAL in order to retrieve records from the database and serialize those records into C# objects. This interaction is described in the next section.
Defining stored procedures results in two primary benefits:
- The procedures can be fine-tuned to perform
JOINoperations when necessary, thereby eleminating overhead in the DAL by restricting the number of database calls required to obtain requested information. For example, when aClientneeds to be loaded in the DAL, theBTPBGetClientprocedure will not only retrieve the associatedClientrecord - it will also obtain the relevantClientTyperecord corresponding to the requested client via aLEFT JOIN. So, for one single database call, two pieces of information were returned. - The DBL can be unit tested by testing each of the procedures to ensure data flows into and out of the database correctly. Once the stored procedures are tested and function well, we can be assured that the DAL will be receiving and serializing data correctly.
DAL
Our data access layer is written in C# as a .NET Core library, making use of MySQL data client libraries and a custom entity framework encapsulating the database schema.
High-level interfaces are designed to capture the key characteristics of the tables in the database. An example of one such interface is the IDatabase interface, which defines the following contract:
public interface IDatabaseObject : IIdLoadable
{
/// <summary>
/// The ID of this entity in the database.
/// </summary>
int Id { get; }
/// <summary>
/// Saves this entity to the database.
/// </summary>
void Save();
/// <summary>
/// Drops this entity from the database.
/// </summary>
void Remove();
/// <summary>
/// Creates a blank, default version of this entity.
/// </summary>
void Initialize();
}
As can be inferred, these interface methods mimic the stored procedure schema discussed in the DBL section; when implemented, the stored procedures in the database can be invoked via the MySQL data client library, and the responses can be parsed into C# objects.
The purpose of the DAL is to facilitate these database transactions, and pass the serialized C# representations of database records to the front end, where the data can be displayed and manipulated by the user of the platform.
In total, 15 high level interfaces are defined in the DAL to encapsulate the DBL. Classes are defined for each table in the database, and they implement one or more of these interfaces in order to define how the data is represented in object format.
Front End (ASP.NET)
If you couldn’t tell by now, I’m a .NET geek. Our front end is also written in a .NET framework called ASP.NET. This framework allows us to easily write bootstrap-driven “HTML” for our pages, build routing mechanisms and user flows using C#, as well as to interface with our DAL which gets packaged with our website as a .dll. I put HTML in quotes because the language used to build the pages is technically not HTML - it’s called Razor, which is essentially HTML with in-document C# scripting capabilities. Here’s some sample Razor code:
<tbody>
@foreach (Project p in ViewData["Projects"] as List<Project>)
{
<tr class="table-active">
<td>@Html.ActionLink(@p.Title, "Project", "Projects", new { projectId = p.Id })</td>
<td>@p.Description</td>
<td>@p.Created</td>
<td>@p.Documents.Capacity</td>
</tr>
}
</tbody>
As you can see, it is still a simple HTML table, but the table is populated in a foreach loop in C#! Pretty nice, huh?
The MVVM (model view view-model) design pattern is implemented in the BTPBuddy website.
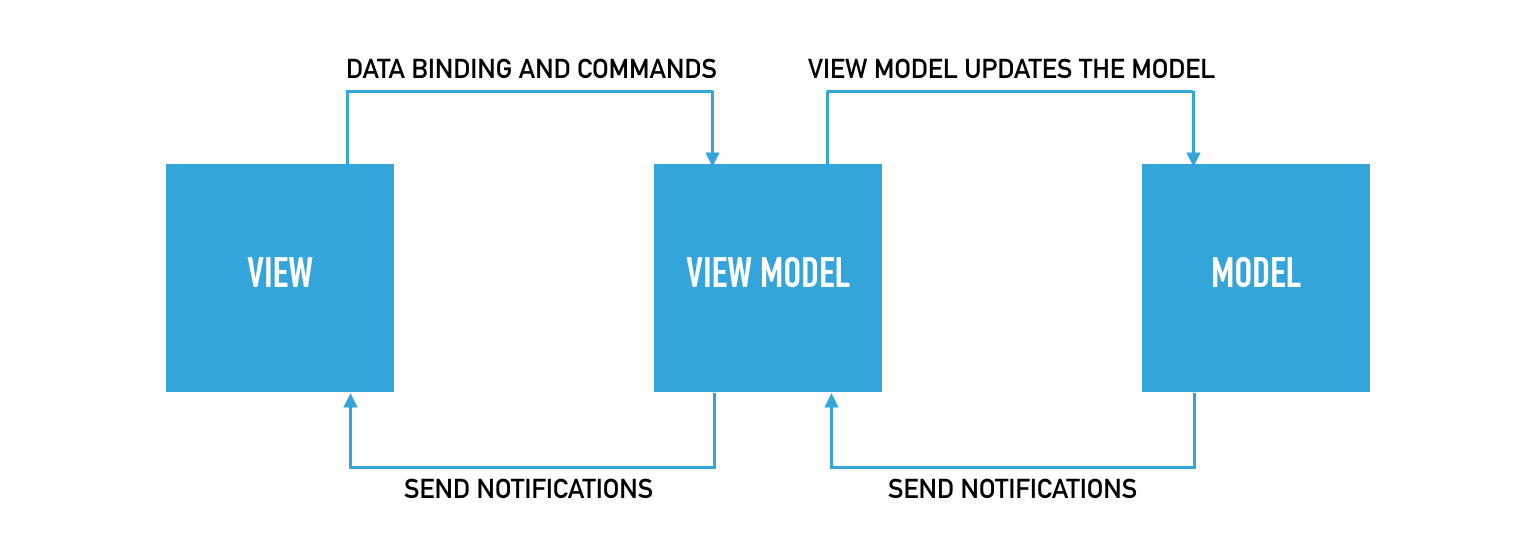

The model layer in our MVVM implementation is the DAL, and any required view models are defined in the website solution.
Reflection
Developing BTPBuddy has been an amazing learning experience for me. It has solidified my understanding of platform architecture, database design, and ASP.NET. The most impactful difficulties I encountered while developing the MVP were almost all related to UX design on the front end, as I have very limited experience in front-end design. As a result, our MVP is certainly lacking in the flashy-front department… However, my team and I all agree that the most important thing at this final stage is that our platform functions correctly, and allows users to perform the basic operations defined in our initial functional requirements. I will of course continue to try and develop the sexier features such as AI-based tagging algorithm integration.